🔮 Vem vinner AI-rejset? Det stängda eller det öppna?

Hur ser framtiden för AI ut? Och vilka kommer att komma ut som AI-vinnare? Ja, det är 10.000-kronorsfrågan (fast i nutid ^jättemycket mer stålar) som rekordmånga tech-människor, investerare, beslutsfattare, politiker och vanliga dödliga klurar kring just nu.
Frågan om AI-vinnare är långt ifrån en enkel 🥜 att ge sig på. Snarare komplex, motsägelsefull, proppad av gråzoner och frågetecken. Dessutom är jag inte själv någon programmerare som kan granska kod, utan en simpel teknikbesatt ekonom. Ändå tänkte jag försöka attackera denna ganska tekniska fråga (dock så icke-tekniskt beskrivet som jag bara kan).
Om jag irrar bort mej bland resonemangen. Om jag tappar dig på vägen. Och/eller om jag har missuppfattat vissa saker. SORRY! Jag har gjort mitt bästa för att sätta på mig den pedagogiska hatten och hålla tungan rätt i munnen. Och samtidigt krama om ansiktet 🤗#HuggingFace. Vad sjutton det sista betyder, ja det kommer du att veta snart.
När det kommer vem-vinner-AI-rejset finns det dessutom massvis av både möjligheter och risker som inte fick plats i just den här texten – däremot i en massa annat som jag har skrivit tidigare (bland annat här, här och här).
Nu till temat och vem som kan tänkas vinna; AI-världens David:s eller Goliat:s. Och i slutet av denna långa post kommer argument för när man som företag / organisation bör välja 📪 stänga vs mer 📭 öppna AI-modeller som grund när man utvecklar egna AI-lösningar.
Då kör vi!
/ Judith
Hur ser då framtiden för AI ut?
Tja, det finns framför allt två olika vägar som utvecklingen skulle kunna ta; det stängda och/eller det öppna spåret.

Spår 1: Giganterna vinner🥇🥈🥉
🔮 En framtid av ett fåtal stora tech-bolag som med stängda modeller kammar hem det mesta
Det vi har sett så här långt i AI-utvecklingen är att ett fåtal redan ledande techbolag – så kallad Big Tech – varit de som imponerat och dominerat. Förutom Alphabet (Google), Meta, Amazon och Microsoft hittar vi också OpenAI såklart (backade av Microsoft), men också spelare som Anthropic (backade av Amazon & Google). Och ytterligare några till. Fram till nu har modeller från den här typen av bolag legat sådär 6-18 månader före i utvecklingen.
Anledningen att dessa giganter har haft ett försprång när det kommer till AI beror på att det har krävts ett gäng kritiska pusselbitar för att kunna träna upp stora imponerande AI-modeller. Pusselbitar som består av enorma mängder data (läs hela internet + lite till), massvis av pengar (sådär över 100 miljoner dollar) och teknisk kompetens för att utveckla de absolut bästa grundmodellerna; Foundation Models och LLMs.
Antingen går vi mot en framtid där dessa vinnare utvecklar en ännu större AI-överlägsenhet och kammar hem hela vinsten. Ett fåtal tech-giganter som tillsammans skapar en form av oligopol som stänger ute alla andra (hey, för om ett fåtal modeller är mycket bättre, varför skulle vi välja något annat?). Något som skulle kunna leda till en koncentration av makt och ekonomisk vinning som vi aldrig tidigare har skådat. Speciellt om AI visar sig ha den transformerande effekten på ekonomin och samhället som många förutspår.

Och deras modeller, ja de har fram tills nu framför allt varit stängda (inte open source). Sannolikt för att kunna behålla hemligheten till alla imponerande framsteg för sig själva. Och för att kunna ta bra betalt. I artikeln här under har jag tidigare dykt ner i vad just ett sådant utfall skulle kunna betyda.

Men att vinnarna tar allt är långt ifrån säkert. Låt oss tittat på det andra spåret.
Spår 2: En mer öppen AI-utveckling
🔮 En framtid där många fler vinnare får plats
Eller så går vi mot en framtid där en massa mer öppna modeller börjar ta fart och bli tillräckligt vassa för att kunna konkurrera. Där både du och jag använder olika mer öppna modeller i vår vardag. Men också där företag och organisationer väljer dessa modeller som grund när de utvecklar egna AI-tjänster. Och öppen innebär till stor del open source. Vad det betyder i AI-sammanhang kommer jag snart att komma in på, låt oss först reda ut begreppet open source.
Open source, eller öppen källkod på svenska, är inget nytt under solen. När jag själv började jobba med internet 2006 var det mestadels open-source-grejer som vi sysslade med. Vi byggde våra sajter i programmeringsspråket PHP, använde publiceringssystemet Wordpress och databasen MySQL för datalagring. Allt open source, men inte bara när det kommer till tekniken. Vi gillade också att prata om internet som en öppen och fri plats. Tilläggas bör nämligen att öppen källkod inte bara är en teknisk fråga utan för många också ett sätt att se på teknik – där dess förespråkare ofta lyfter aspekter som transparens, samarbete och gemenskap. Läs mer här.
Men open source var också ganska rörigt (liksom stora delar av internet på den tiden). Och det var jättemycket krångligare att skapa saker om man inte kunde koda jämfört med idag.

På samma sätt som det sedan länge har funnits öppen källkod på internet så finns den öppna modellen även när det kommer till AI.
AI-modeller med öppen källkod innebär att alla inte bara kan använda dessa modeller, utan också att utvecklare från hela världen kan vara med och göra dem ännu bättre. Förutom att källkoden finns öppen är även datan som har använts för att träna modellen tillgänglig för alla (åtminstone i skolboksexemplet). Om man vill använda en öppen AI-modell, ja då kan man ganska fritt bestämma hur man vill använda både modellen och datan vilket ger stor flexibilitet. Man kan alltså knåda om dessa modeller genom så kallad fine tuning, så att de passar för det som man vill göra.
🚨 Just detta “knåda om” betyder också att open source-AI kommer med en hel del utmaningar och risker. Inte minst när det kommer till missbruk av tekniken. Det är framför allt öppna AI-modeller som idag används för att skapa deep fakes i syftet att luras och vilseleda – oavsett om det gäller kriminell aktivitet eller att manipulera politiska val. Men också för att skapa riktigt kassa saker som det här ➡️ It’s Not Just Taylor Swift: AI-Generated Porn Is Targeting Women And Kids All Over The World.
Låt oss nu addera lite tekniska termer. Samt för- och nackdelar med de två alternativen
Jag brukar försöka undvika buzzwords i den mån det är möjligt. Men i det här fallet behöver vi addera lite begrepp. Säg först hej till termen “proprietära modeller”.
➡️ Proprietära AI-modeller (de stängda)
🙄 Vad sjutton betyder ordet “proprietär”? Jo, det är ett adjektiv som betyder en persons eller ett företags egendom.
Proprietära AI-modeller är modeller där man inte delar med sig av själva grundtekniken utan “bara” åtgång till tillämpningen (ofta via API:er). Källkoden är stängd vilket betyder att ingen utanför exempelvis OpenAI kan se hur deras algoritmer, datamängder och teknik bakom ser ut. För proprietär modeller finns restriktioner kring hur de kan användas. Som individ eller företag kan man inte fritt justera modellerna på de sätt man önskar utan är ofta mer begränsad när det kommer till anpassning.
Exempel på proprietär modell är:
- GPT4 från OpenAI (den som ligger till grund för ChatGPT) + andra modeller från OpenAI.
- Modellen Gemini som är Google Deepminds flaggskeppsmodell (som just nu dock befinner sig lite i blåsväder). Modellen är “multimodal” vilket betyder att den kan lösa olika typer av uppgifter (läs mer här).
- AI-bolaget Athropic har ett par stängda AI-modeller som går under namnet Claude.
Några av fördelarna med proprietära AI-modeller kommer här:
- I dagsläget är det de stängda modellerna som fortfarande levererar bäst resultat rent tekniskt.
🏆 LMSYS Leaderboard är en plattform där utvecklare rankar olika LLM:s (språkmodeller) utifrån hur de presterar. I skrivande stund är de högst 11 rankade modellerna proprietära (med undantag av en modell från Alibaba som jag inte vet något om). På plats 12 hittar vi den första öppna modellen från Mistral. Och på plats 17 Llama 2 från Meta + Microsoft. Gå in och kolla själv här: huggingface.co/leaderboard
- Ur ett användarperspektiv är proprietära modeller ofta enkla att använda (via snygga gränssnitt) och det går snabbt även för företag att komma upp på AI-banan med hjälp av API:er.
- Ur AI-bolagets (giganternas) perspektiv innebär “hålla koden hemlig” att det blir svårare för andra att kopiera hemligheten. (Samtidigt går man miste av den kraften som finns i en open-source-community som hjälper till att utveckla modellen vidare).
- Proprietära AI-modeller kommer ofta med licensavgifter / prenumerationskostnader vilket är toppen för AI-bolaget som givetvis vill tjäna pengar. Och man kan ta duktigt betalt för åtkomst om modellen är tillräckligt imponerande. (En hög prislapp inte lika toppen för slutanvändare och företag som vill använda AI-modellen för egna tillämpningar).
- En fördel för samhället och världen är att dessa modeller är lättare att begränsa när det kommer till missbruk. Ber du ChatGPT hjälpa dig med kriminell aktivitet så får du högst sannolikt ett nej. Eller om du ber en annan stängd modell att generera tvivelaktiga bilder på kända politiker, ja då får du förhoppningsvis också ett nix-pix.
➡️ De mer öppna AI-modellerna (olika grader av open source)
Vi har redan gått igenom att öppna modeller i kontexten av AI betyder att källkod, data och community är i centrum av utvecklingen. Och att utvecklare från världens alla hörn kan vara med och förbättra modellerna. När det kommer till öppna modeller är även licensavgifter antingen slopade eller lägre än för proprietära modeller.
Låt oss lista några exempel på mer öppna AI-modeller.
- Franska Mistral är just nu Europas största AI-löfte och har tagit in nästan 500 miljoner Euro i riskkapital. Här kan du läsa mer.
- Stability AI är ett spännande bolag som bland annat skapat text-till-bild-modellen Stable Diffusion.
- BLOOM är en öppen AI-modell som har utvecklats i samarbete mellan över 1000 forskare. Läs mer här.
Några av fördelarna med öppna AI-modeller är:
- Med öppen källkod kan forskare, utvecklare och andra intressenter granska hur AI-modellerna funkar. Något som ger en större transparens när det kommer till sådant som bias, fel och säkerhetsbrister.
- De öppna modellerna kan innebära att innovation och förbättringar går snabbare (om de blir poppis dvs).
- Eftersom kostnaden är lägre kan fler få tillgång till avancerade AI-funktioner utan att det behöver kosta skjortan. Förutsatt att man kan lösa den tekniska biten med att använda och justera modellen det vill säga.
- Ofta är open source-modeller mer flexibla och går att anpassa bättre för olika tillämpningsområden.
- Och! Det som är intressant med öppna AI-modeller för många företag, ja det är det faktum att man inte bara kan kontrollera modellerna utan också datan. När data privacy är extra viktigt, ja då kan open source kännas som ett bra alternativ.
Även om de öppna modellerna (ännu) inte kan matcha OpenAI eller Google när det kommer till teknisk nivå är det inte alltid som bäst-i-klassen behövs. Det finns en massa tillämpningar där good enough is perfect. I många fall är det andra aspekter som är viktigare. Som att modellerna går att justera eller att man kan styra över hur datan används och lagras.
Utmaningen med att välja AI-lösningar med öppen källkod är dock att det ofta är krångligare – då det både kräver teknisk kompetens och egen infrastruktur (på samma sätt som det år 2006 var krångligt att sätta upp en Wordpress-sajt). Dock håller detta på att förenklas i och med att olika verktyg och ramverk utvecklas för att förenkla fine-tuning, hantering av data och tillämpning. Den största plattformen där allt samlas har det något märkliga namnet 🤗 Hugging Face.
🤗 Hugging Face är en plattform och community för utveckling och forskning inom AI. Här publiceras information om olika modeller, API:er med mera. På sajten finns över 500,000 modeller publicerade och över 100,000 olika datasets. Länk: huggingface.co
Innan vi avslutar det där med öppna modeller bör tilläggas att en del av dem kommer med restriktioner gällande användning, exempelvis att de inte kan användas för kommersiellt bruk utan bara för “non-commercial research purposes”.
➡️ I verkligheten är många modeller en mix av stängt & öppet
I realiteten är det dock inte så enkelt som att AI-modeller antingen är stängda eller öppna. Snarare är många en mix av det slutna och det öppna. Där det dessutom inte bara finns olika nivåer av öppenhet utan också delade meningar kring vad som kan kallas för open source (en strikt definitionen finns dock här). Vissa modeller som hävdar att de är öppna kan vara det utifrån vissa aspekter, men inte hela vägen open source. Snurrigt, jag vet. Vill du nörda ner dig mer i detta kan jag tipsa om den här artikeln.
Ett exempel på mix är franska Mistral vars affär består av två delar; en modell som är öppen och gratis för alla. Och en annan del som är stängd och påminner om OpenAI:s affärsmodell (att ta betalt av företag för att komma åt modellen via API).
“The Mistral AI strategy here clearly aims to be a hybrid, ‘best of both worlds’ approach” - AI Business
Börjar du AI-tröttna? Låt oss först slänga in en GIF för att lätta upp. Och sedan prata lite om trender vilket kanske kan få dig att piggna till.

Giganterna / Big Tech har nämligen allt mer börjat lansera mer öppna modeller. Varför då?, tänker du kanske. Låt oss kika på det.
En ny trend? Big Tech satsar mer på öppna modeller
Först ut bland Big Tech (såvitt jag och ChatGPT vet) att släppa öppna och hyfsat imponerande AI-modeller var Google som 2018 släppte BERT. Ett mer aktuellt exempel är Meta vars modeller i familjen Llama är “open source” (även om vissa menar att de inte är speciellt öppna). Den senaste modellen är i skrivande stund Llama 2 som du kan läsa mer om här.
Yann LeCun, Chief AI Scientist på Meta, har i en intervju med TIME sagt så här ⬇️ (läs hela intervjun här).
“The future has to be open source, if nothing else, for reasons of cultural diversity, democracy, diversity.” - Yann LeCun, Chief AI Scientist, Meta
Även Google börjar få fart när det kommer till öppenhet. Sedan en tid har man bland annat modellerna PaLM 2 och AlphaFold. Och för två veckor sedan släppte man sin “öppna” modell Gemma som är en light-version av den större modellen Gemini. Men där även Gemma har kritiserats för att kalla sig för “öppen” ➡️ Google's Latest AI Language Models Are Open Weight, Not Open Source (Forbes).
Vilket spår kommer att vinna?
🔮 Låt oss nu prata framtid. Som vanligt med framtiden så vet vi inte vem som kommer att dominera; de stängda eller öppna AI-modellerna. Observera att jag skriver dominera den här gången istället för vinna. Sannolikt är nämligen att vi kommer att få se dem båda. Antingen existera sida vid sida, eller till och med samarbeta med varandra och/eller komplettera varandra.
🦓 Jag tror alltså inte på en ett antingen eller, utan ett zebrarandigt mellanting där vi använder olika modeller för olika tillämpningar.
- I vissa fall kommer i-absoluta-framkant-teknik sannolikt att vara viktigt för oss. Och då kanske vi väljer proprietära modeller. Detta kan tänkas att gälla både för oss som individer (att vi exempelvis betalar för ChatGPT), men också för utvecklare och företag som betalar för att komma åt modellen via API. Detta gäller framför allt när vi vill lösa uppgifter av stilen general-purpose.
- I en massa andra sammanhang kommer i-absoluta-framkant-teknik inte att vara nödvändigt. Där good enough räcker för massvis av tillämningar. Framför allt när vi behöver anpassa våra lösningar till specifika och smala uppgifter.
- Stora proprietära modeller som GPT4 (OpenAI) och Gemini (Google) kommer sannolikt också att vara för dyra för många affärscase. Något som gör att organisationer kommer att välja billigare öppna lösningar. Eller mindre proprietära modeller som inte är lika dyra.
Vill du läsa mer om ett liknande resonemang kan du göra det i den här superbra artikeln ➡️ Will Enterprise AI Models be “Winner Take All? (bilden nedan kommer från artikeln).
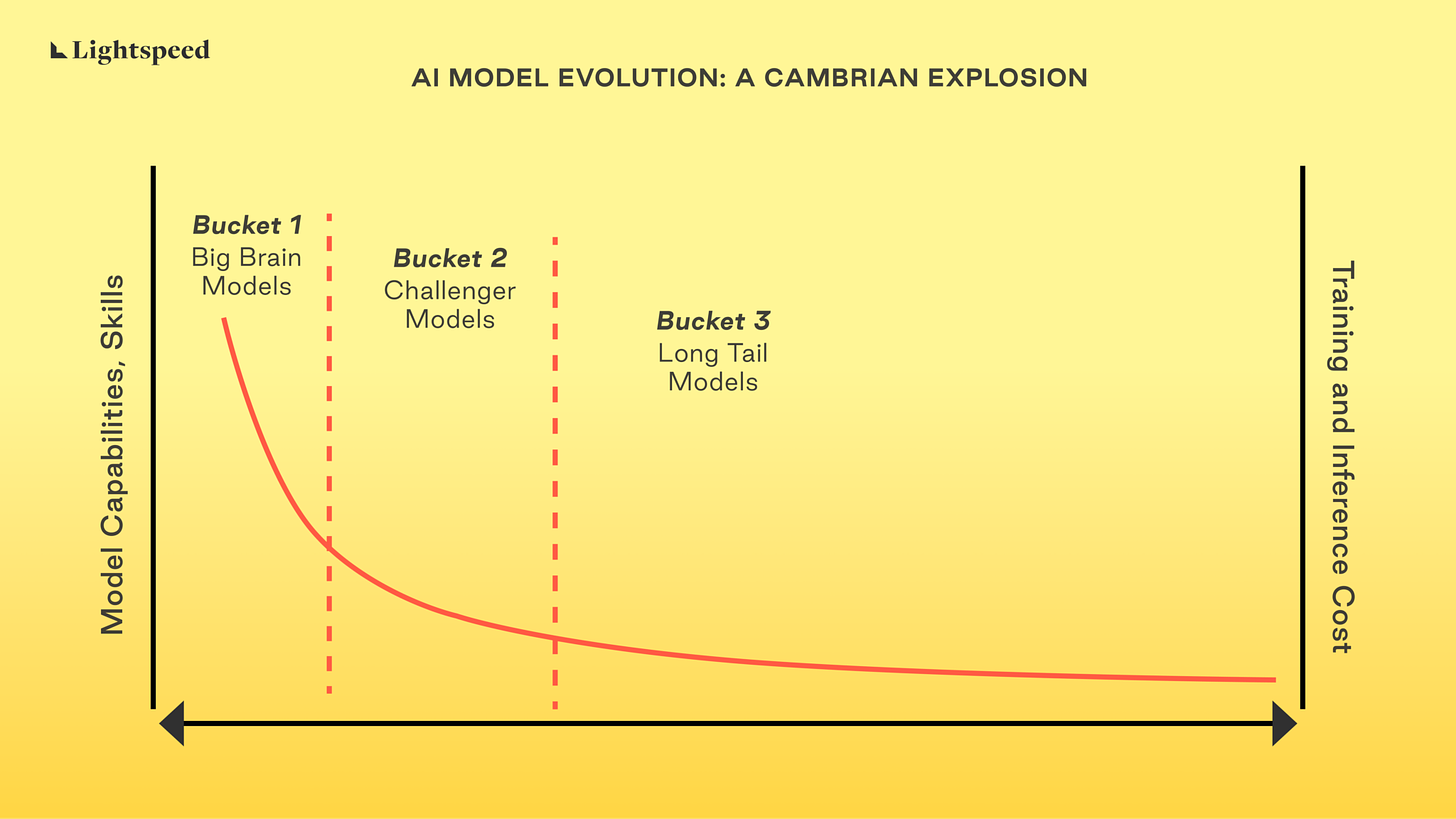
Nu behöver vi runda av 😅
Jisses vad mycket begrepp och tekniskt snack. Snyggt jobbat till alla er som tog er hela vägen hit!
Avslutningsvis kommer här 16 exempel på företag som har utvecklat egna AI-lösningar med hjälp av open source-modeller ➡️ How enterprises are using open source LLMs: 16 examples. Och du har garanterat läst om Klarnas AI-assistent för kundservice som har utvecklats med OpenAI:s proprietära modell som grund.
/ Judith
➡️ Missa inte att prenumerera på mitt nyhetsbrev Plötsligt i Framtiden på Substack! Där får du veckovisa trendspaningar på temat teknik och hållbarhet.